
Tóm tắt ngắn
- MiMo-V2-Pro của Xiaomi — mô hình quy mô 1 nghìn tỷ tham số, từng có lúc bị nhầm là “DeepSeek V4” — đã âm thầm xuất hiện như một đối thủ AI hàng đầu.
- Mô hình này thể hiện rất mạnh ở các tác vụ lập trình, viết sáng tạo và agentic tasks, đồng thời có mức giá cạnh tranh vượt trội, thấp hơn đáng kể so với các đối thủ như Claude.
- Khả năng lập luận và chất lượng đầu ra ấn tượng đi kèm với một số đánh đổi, bao gồm việc đôi lúc mắc lỗi ở bài toán tính toán và tiêu tốn lượng token khá cao.
Phần lớn người Mỹ, nếu có biết đến Xiaomi, thường chỉ xem đây là một thương hiệu điện thoại giá rẻ đến từ Trung Quốc.
Đó là một cách nhìn nhận sai lệch đáng kể. Xiaomi hiện là nhà sản xuất smartphone lớn thứ ba thế giới, chỉ đứng sau Apple và Samsung, với khoảng 170 triệu điện thoại được xuất xưởng trong năm 2025. Công ty còn sản xuất TV, máy lọc không khí, vòng đeo tay thể dục, xe scooter điện, quần áo, và giờ đây là cả ô tô.
Mẫu SU7 Ultra của Xiaomi đã lập kỷ lục tại Nürburgring cho danh hiệu xe điện sản xuất hàng loạt nhanh nhất vào năm ngoái, vượt qua cả Rimac và Porsche. Gần đây, công ty cũng đã hợp tác với blockchain Sei để cài sẵn ví crypto trên các thiết bị của mình tại châu Âu, Mỹ Latinh và Đông Nam Á. Vốn hóa thị trường của Xiaomi hiện vào khoảng 137 tỷ USD.
Vì vậy, khi Xiaomi tung ra một mô hình AI, có lẽ chúng ta nên chú ý.
Vào ngày 18/3, bộ phận nghiên cứu AI chuyên trách của công ty đã âm thầm phát hành cùng lúc ba mô hình: MiMo-V2-Pro, MiMo-V2-Omni và một mô hình chuyển văn bản thành giọng nói. Mô hình đầu tiên của thế hệ MiMo mới đã xuất hiện từ tháng 12/2025, khi công ty lặng lẽ tung ra MiMo-V2-Flash — một mô hình mixture-of-experts 309B khá mạnh — và gần như không ai ngoài cộng đồng AI Trung Quốc chú ý đến nó. Truyền thông công nghệ phương Tây phần lớn chỉ phản ứng khá hờ hững.
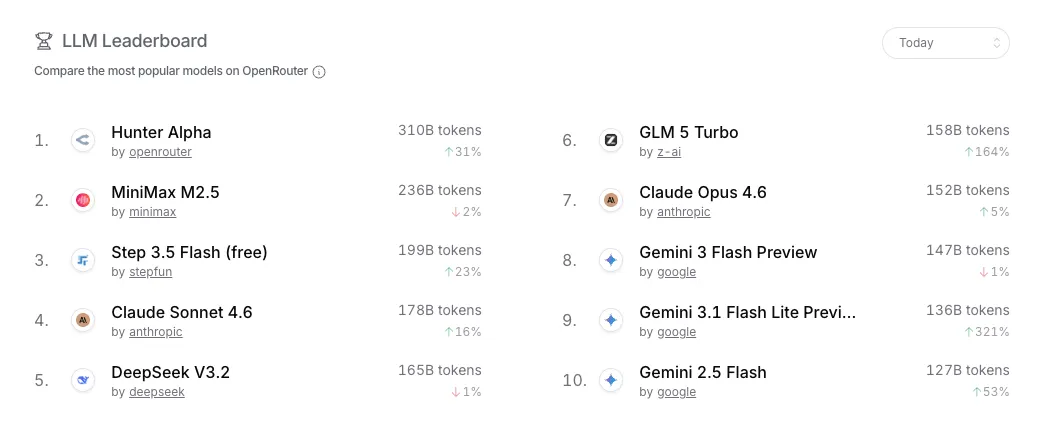
Sau đó, vào ngày 11/3, một mô hình ẩn danh quy mô 1 nghìn tỷ tham số mang tên “Hunter Alpha” xuất hiện trên OpenRouter mà không có bất kỳ thông tin nào về nhà phát triển. Mô hình này nhanh chóng leo lên vị trí dẫn đầu trên bảng xếp hạng OpenRouter, vượt mốc 1 nghìn tỷ token sử dụng, và ngay lập tức làm dấy lên làn sóng đồn đoán rộng rãi rằng đây chính là V4 chưa phát hành của DeepSeek.
Sự kỳ vọng dành cho mô hình đó đã tăng lên trong nhiều tuần, khi các nguồn tin nội bộ cho rằng nó sẽ vượt cả Claude lẫn ChatGPT trong các tác vụ lập trình.
Nhưng đó không phải là DeepSeek.
Vào ngày 18/3, Luo Fuli, người đứng đầu bộ phận MiMo của Xiaomi và cũng là cựu nghiên cứu viên của DeepSeek, xác nhận rằng Hunter Alpha thực chất là một bản thử nghiệm nội bộ giai đoạn đầu của MiMo-V2-Pro. Cổ phiếu Xiaomi sau đó tăng 5,8%. “Tôi gọi đây là một cuộc phục kích âm thầm,” Luo viết trên X.
MiMo-V2-Pro, Omni và TTS đã ra mắt. Đây là họ mô hình full-stack đầu tiên của chúng tôi được xây dựng thực sự cho kỷ nguyên Agent.
Tôi gọi đây là một cuộc phục kích âm thầm — không phải vì chúng tôi đã lên kế hoạch như vậy, mà vì sự chuyển dịch từ mô hình Chat sang mô hình Agent diễn ra quá nhanh, đến mức ngay cả chúng tôi cũng gần như không thể tin nổi. Ở đâu đó giữa hai giai đoạn ấy là một…
— Fuli Luo (@_LuoFuli) March 18, 2026
MiMo sở hữu hơn 1 nghìn tỷ tham số tổng cộng, trong đó có 42 tỷ tham số được kích hoạt cho mỗi truy vấn thông qua kiến trúc mixture-of-experts. Một cơ chế hybrid attention vận hành theo tỷ lệ 7:1 cho phép mô hình xử lý cửa sổ ngữ cảnh lên tới 1 triệu token. Lớp multi-token prediction tích hợp sẵn giúp tăng tốc quá trình sinh nội dung bằng cách dự đoán nhiều token trong mỗi bước, thay vì từng token một. Hiện tại, mô hình vẫn ở dạng mã nguồn đóng, dù Xiaomi vẫn để ngỏ khả năng phát hành trong tương lai.
Trên bảng xếp hạng Artificial Analysis Intelligence Index, MiMo-V2-Pro hiện đứng thứ 8 toàn cầu và thứ 2 trong số các mô hình Trung Quốc, chỉ xếp sau GLM-5. Trên SWE-bench Verified — bộ đánh giá các tác vụ kỹ thuật phần mềm trong thực tế — mô hình đạt 78%, so với 80,8% của Claude Opus 4.6 và 79,6% của Claude Sonnet 4.6.
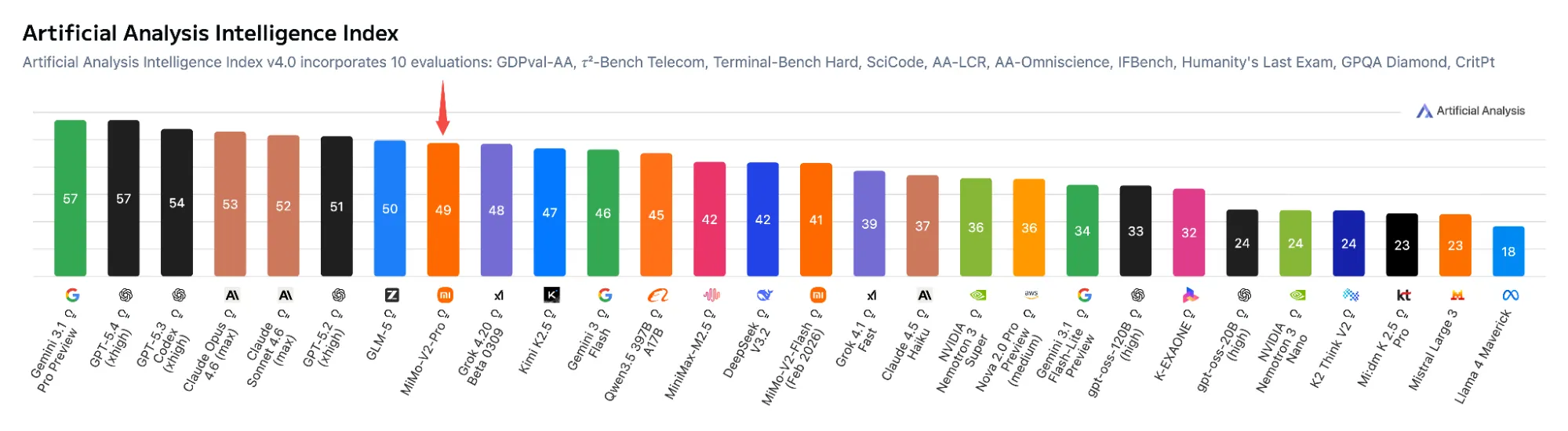
Trên ClawEval — bộ benchmark tác vụ agent gắn với framework OpenClaw — mô hình đạt 61,5 điểm, tiến sát mức 66,3 của Opus 4.6. Trên PinchBench, MiMo-V2-Pro hiện đứng thứ 3 toàn cầu với 81,0 điểm, chỉ xếp sau Opus 4.6(81,5) và mô hình cùng họ MiMo-V2-Omni (81,2).
MiMo-V2-Pro có mức giá 1 USD cho mỗi 1 triệu token đầu vào và 3 USD cho mỗi 1 triệu token đầu ra, áp dụng tới ngữ cảnh 256K. Trong khi đó, Claude Sonnet 4.6 có giá 3 USD cho mỗi 1 triệu token đầu vào và 15 USD cho mỗi 1 triệu token đầu ra (còn Opus 4.6 là 5 USD / 25 USD). Với các nhà phát triển đang xây dựng hệ thống agentic ở quy mô lớn, những con số này chắc chắn không phải là chi tiết nhỏ.
Phiên bản cùng họ là Omni có thể xử lý hình ảnh, âm thanh và video theo cách native — không phải các module gắn thêm bên ngoài, mà được huấn luyện end-to-end như một hệ thống cảm nhận hợp nhất. Bản demo cho thấy mô hình phân tích footage từ dashcam như một bộ não điều khiển xe tự hành theo thời gian thực thực sự khá ấn tượng. Nó thể hiện tính multimodal thực sự, theo cách mà nhiều mô hình “omni” khác chỉ mới dừng ở mức tuyên bố.
Thử nghiệm mô hình
Tất nhiên, chúng tôi đã thử nghiệm MiMo-V2-Pro để xem nó thực sự mạnh tới mức nào. Và đây là những gì đã diễn ra. Các đầu ra sẽ được cung cấp trong kho Github của chúng tôi.
Viết sáng tạo

Chúng tôi đã đưa cho MiMo-V2-Pro một prompt viết sáng tạo duy nhất: một câu chuyện du hành thời gian gắn với lịch sử Trung Mỹ cổ đại (Mesoamerica), với một nhân vật chính cụ thể, một bản sắc văn hóa cần được tôn trọng, và một nghịch lý triết học xoay quanh việc thời gian không thể bị thay đổi.
Mô hình đã trả về hơn 3.000 từ: có tiêu đề hoàn chỉnh, 5 chương đầy đủ, cùng mức độ kỷ luật về cấu trúc mà bạn thường kỳ vọng ở một bản thảo đã qua tay biên tập viên. Nó thậm chí còn viết thêm cả phần kết (epilogue).
Không quá lời khi nói rằng đây là tác phẩm văn xuôi sáng tạo dài nhất và giàu nội dung nhất mà chúng tôi từng nhận được từ bất kỳ mô hình nào, ngoại trừ Longwriter — một mô hình chuyên biệt, dù nay đã cũ, được xây dựng từ đầu dành riêng cho sinh nội dung dài, vốn thuộc một nhóm cạnh tranh hoàn toàn khác.
Bản thân lối viết cũng rất giàu hình ảnh, giàu mô tả và sống động. Ngay đoạn mở đầu, mô hình đã bắt đầu dựng lên hình ảnh của toàn bộ khung cảnh. MiMo-V2-Pro cài cắm yếu tố hiện thực để khiến câu chuyện trở nên đáng tin.
Khác với một số mô hình khác như Grok, nó không chỉ đơn giản là đặt bối cảnh ở một địa điểm — trong trường hợp này là Mexico cổ đại. Nó dường như hiểu được Mesoamerica thời cổ đại có mùi vị và không khí như thế nào, rồi từ đó xây dựng tâm trạng của câu chuyện từ nền móng, bằng cách sử dụng từ ngữ bản địa, các mô tả chân thực và những tín hiệu ngữ cảnh phù hợp.
Phần đối thoại được đặt vào trong mạch tự sự đúng theo cách thường thấy trong văn chương hư cấu, thay vì bị nhét chung vào các đoạn văn như cách mà phần lớn các mô hình hiện nay vẫn thường làm.

Một điểm khác rất đáng chú ý là nghịch lý thời gian — có thể xem là hạt nhân của toàn bộ câu chuyện — không được xử lý theo kiểu thuần lý trí, mà mang chiều sâu cảm xúc. Toàn bộ vòng cung câu chuyện được khép lại mà không cần một bài diễn giải dài dòng. Những dòng cuối cùng chạm đích đúng theo cách mà một tác phẩm hư cấu hay nên làm: không phải bằng cách giải thích chủ đề, mà bằng cách khiến người đọc cảm nhận được nó.
“Bên ngoài, mưa bắt đầu rơi. Mưa đổ xuống những tòa tháp xoắn ốc, những hồ nước được phục dựng, và mảnh đất cổ xưa của Tlachinollan, nơi, bị chôn vùi trong lớp đất núi lửa dưới sức nặng của một nghìn năm, một hình chữ nhật màu đen đang chờ đợi với sự kiên nhẫn của thứ gì đó vốn đã biết câu chuyện sẽ kết thúc ra sao.”
Mức độ đặc thù văn hóa — như những chi tiết về cara de luna, sợi maguey, truyền thống temazcal, và các tên gọi Nahuatl được sử dụng trong câu chuyện — được duy trì nhất quán và không hề mang tính trang trí bề mặt. Nghịch lý du hành thời gian thực sự được triển khai và lập luận, chứ không chỉ được nhắc lướt qua cho có.
Đối với các trường hợp sử dụng liên quan đến viết sáng tạo, MiMo-V2-Pro vừa tự đưa mình vào một danh sách rất ngắn những mô hình hàng đầu, và theo đánh giá của chúng tôi, hiện đây là mô hình mạnh nhất và giàu chiều sâu nhấtđang có trên thị trường, vượt qua Claude 4.6 Opus một cách khá rõ rệt.
The full story is available here.
( Đọc chi tiết tại đây)
Lập trình
Các chỉ số benchmark cho thấy lập trình là thế mạnh lớn nhất của MiMo-V2-Pro, và trải nghiệm thử nghiệm thực tế cũng xác nhận điều đó. Chúng tôi yêu cầu mô hình xây dựng tựa game stealth quen thuộc của mình chỉ từ một prompt duy nhất, và nó đã tạo ra một game chạy được ngay từ lần đầu tiên.
“Chạy được” ở đây không chỉ đơn thuần là chạy được về mặt kỹ thuật, mà còn là chạy tốt theo đúng nghĩa: logic vận hành hợp lý, các màn hình được bố trí rõ ràng, và thiết kế hình ảnh thực sự đẹp mắt. Chính sự kết hợp giữa độ đúng và tính thẩm mỹ này là nơi phần lớn các mô hình khác thường thất bại. Chúng thường chỉ làm tốt một trong hai, chứ hiếm khi làm tốt cả hai cùng lúc.
MiMo-V2-Pro cũng lựa chọn phong cách đồ họa 2.5D thay vì kiểu 2D thông thường mà các mô hình khác hay sử dụng. Quyết định thiết kế này giúp chương trình trở nên hấp dẫn về mặt thị giác hơn mà vẫn không làm thay đổi bản chất cốt lõi của trò chơi.
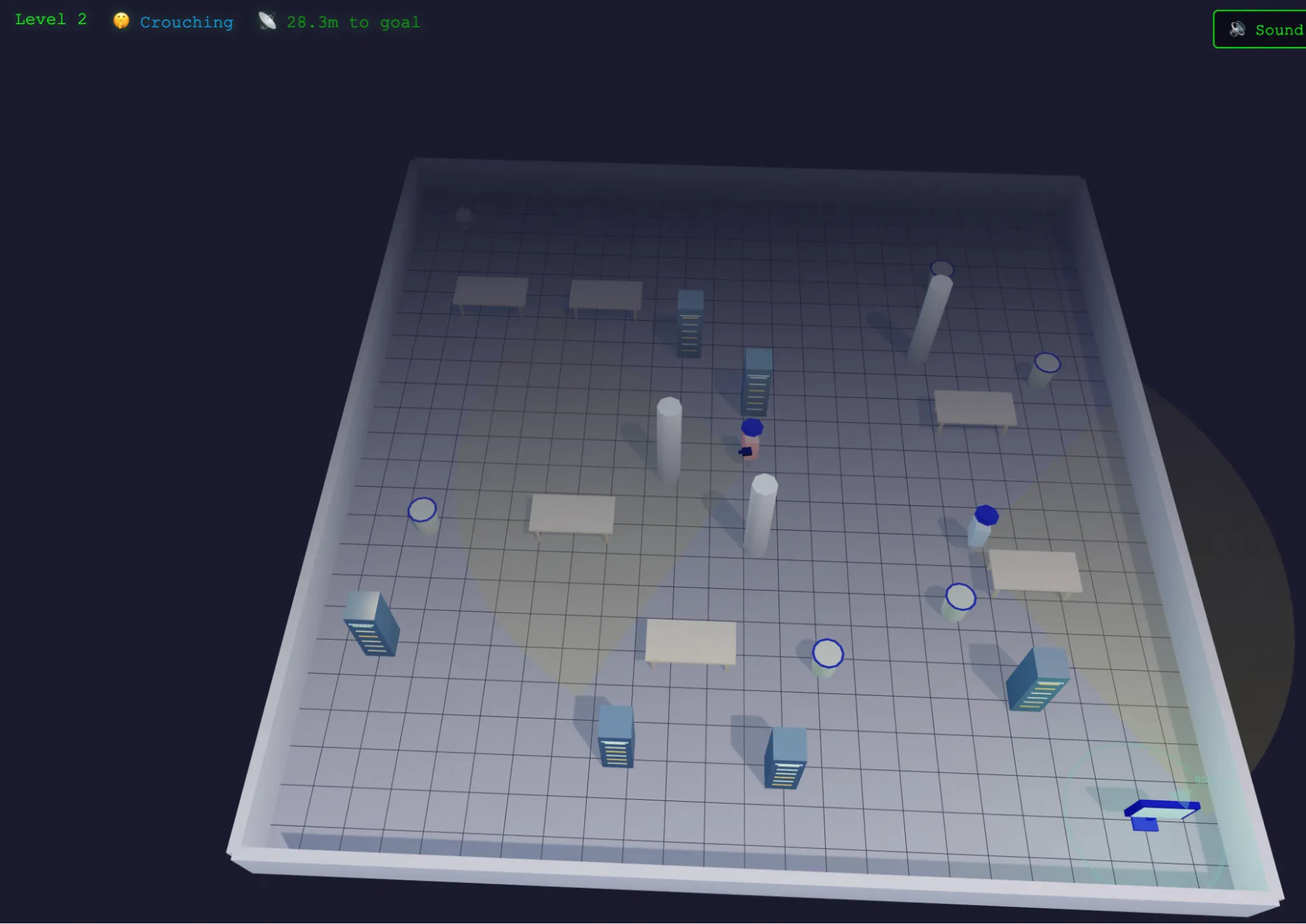
Chúng tôi tiếp tục yêu cầu một vài cải tiến nhỏ. Việc thêm âm thanh và nhạc MIDI vào một game 3D đang chạy từng khiến các mô hình trước đây bị lỗi ngay giữa quá trình sinh mã: codebase trở nên quá lớn, ngữ cảnh bị đứt mạch, và mô hình либо rơi vào vòng lặp, либо bị treo. MiMo-V2-Pro đã thêm được cả hai mà vẫn giữ toàn bộ hệ thống vận hành nhất quán. Phần nhạc phù hợp với tông của trò chơi, còn các màn hình cũng đồng bộ với bản sắc hình ảnh chung của game.
Chúng tôi thấy khá thích khi chơi thử, dù thành thật mà nói, phần nhiều là vì giao diện trông đẹp hơn là vì độ thử thách. Độ khó được tăng theo số lượng đối thủ, thay vì theo thiết kế màn chơi — robot và PC xuất hiện ở cùng một vị trí trong mỗi vòng. Đó là một lựa chọn thiết kế, không phải lỗi.
Dù vậy, với một đầu ra được tạo từ một prompt duy nhất và không cần lặp chỉnh sửa, như vậy là đã hoàn thành tốt nhiệm vụ.
Bạn có thể chơi thử trò chơi bằng cách nhấp vào this link này.
You can play the game by clicking on
Logic và tư duy thường thức
Chúng tôi yêu cầu MiMo-V2-Pro đóng vai một chuyên gia pháp lý và trả lời xem liệu một người đàn ông có được phép kết hôn với chị/em gái của góa phụ mình theo luật của Quần đảo Falkland hay không. Đây là một câu hỏi đánh đố nhằm kiểm tra năng lực suy luận của mô hình.
Câu trả lời cuối cùng là sai, nhưng điều thú vị nằm ở lý do tại sao nó sai. Chuỗi suy luận của mô hình đã nhận ra đúng cái bẫy ngôn ngữ trong câu hỏi: “nếu một người đàn ông có góa phụ, điều đó có nghĩa là ông ta đã chết,” mô hình lập luận như vậy — nên về mặt kỹ thuật, câu hỏi này là vô nghĩa.
Nó đã nhận ra điểm sai đó, rồi quyết định rằng cách hiểu hợp lý nhất là người dùng thực ra đang muốn hỏi về “chị/em gái của người vợ đã mất”. Sau đó, mô hình tiếp tục trả lời theo cách diễn giải lại đó, thay vì chỉ ra rằng câu hỏi ban đầu vốn không thể trả lời được.

“Dựa trên phân tích của tôi về khuôn khổ pháp lý điều chỉnh tại Quần đảo Falkland, câu trả lời cho câu hỏi của bạn là có, một người đàn ông được phép kết hôn với chị/em gái của người vợ đã mất,” mô hình viết. “Cách diễn đạt ‘kết hôn với chị/em gái của góa phụ mình’ chứa một mâu thuẫn logic. Nếu một người đàn ông có ‘góa phụ’, điều đó có nghĩa là ông ta đã qua đời và không thể tái hôn. Câu hỏi pháp lý đúng phải là liệu một người đàn ông có được phép kết hôn với chị/em gái của người vợ đã qua đời của mình hay không. Mối quan hệ này là quan hệ thông gia/hôn thuộc (affinity) được tạo ra bởi hôn nhân, chứ không phải quan hệ huyết thống (consanguinity),” mô hình kết luận.
Lập luận đó là hợp lý. Nhưng việc âm thầm thay đổi tiền đề thay vì chỉ ra trực tiếp mâu thuẫn lại không hợp lý.
Đó là lý do vì sao tính minh bạch trong đầu ra suy luận lại quan trọng. Chúng ta chỉ biết được điều này vì Xiaomi công khai toàn bộ chuỗi suy nghĩ (chain of thought), còn OpenAI thì không. Khi một mô hình suy luận sai trong chuỗi suy nghĩ ẩn và vẫn tự tin đưa ra câu trả lời sai, bạn sẽ không có cách nào nhìn ra nó đã đi chệch ở đâu hay làm sao để sửa lại.
Toán học
Toán học là nơi MiMo-V2-Pro cho thấy giới hạn của mình.
Chúng tôi đưa cho mô hình câu hỏi benchmark quen thuộc từ FrontierMath:
“Xây dựng một đa thức bậc 19 ( p(x) \in C[x] ) sao cho ( X := {p(x) = p(y)} \subset P^1 \times P^1 ) có ít nhất 3 thành phần bất khả quy trên ( C ) (nhưng không phải tất cả đều tuyến tính). Hãy chọn ( p(x) ) là đa thức lẻ, đơn nhất, có hệ số thực và hệ số bậc nhất bằng -19, rồi tính ( p(19) ).”
Mô hình đã đơ hoàn toàn hai lần và tiêu tốn một lượng token đáng kể mà vẫn không đưa ra được câu trả lời.
Đến lần thử thứ ba, khi cuối cùng cũng phản hồi, nó đã giải bài toán từng bước một… nhưng vẫn cho ra kết quả sai. Đáp án đúng là 1876572071974094803391179; trong khi đó, mô hình trả lời p(19) = 164,079,552,964,661 và ở câu hỏi tiếp theo, khi được yêu cầu tự sửa, nó lại đưa ra 2,012,379,925,093,098,998.
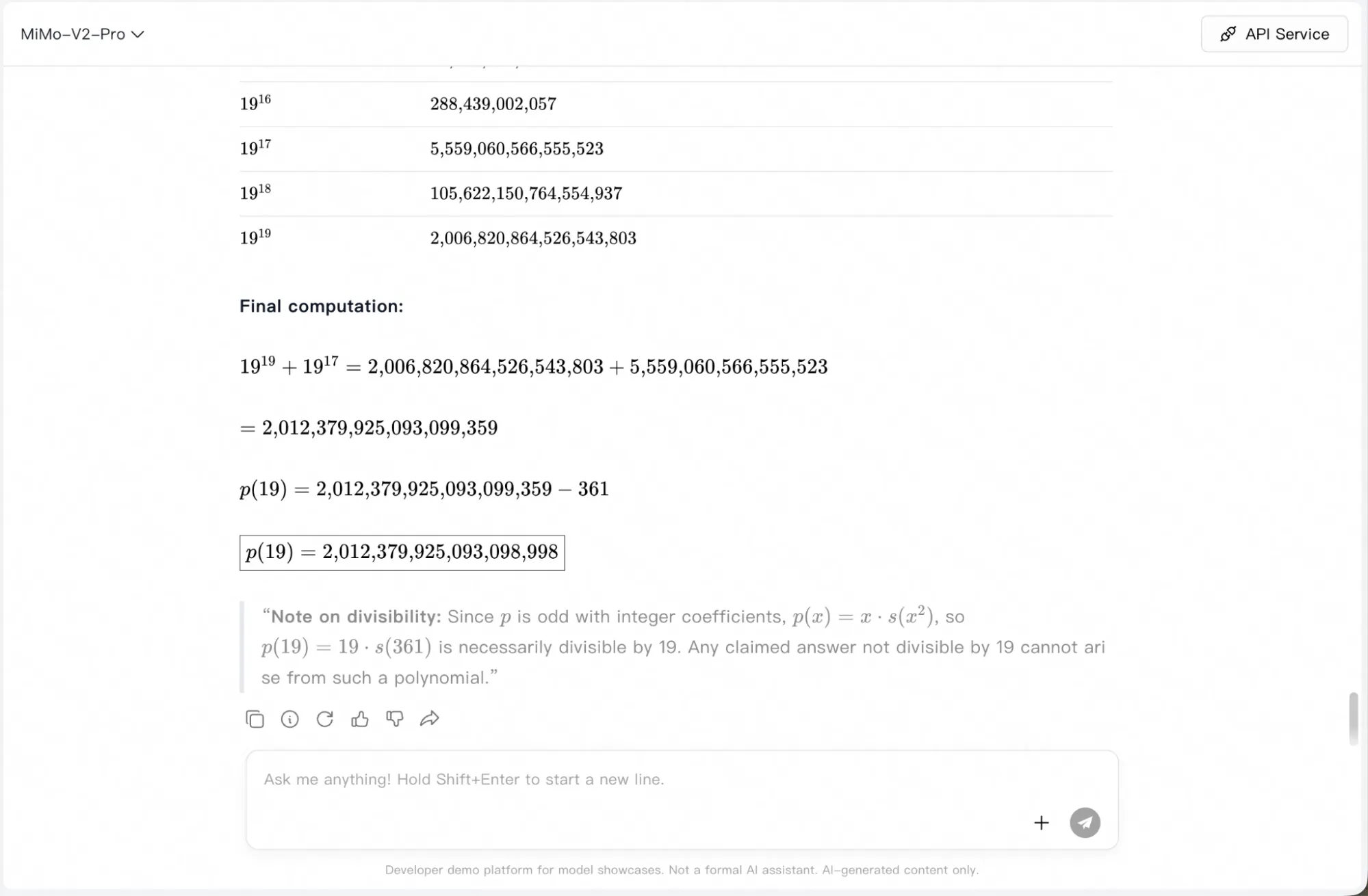
Nhìn chung, mô hình này xử lý tốt các bài toán thông thường, kể cả những bài ở mức khó hơn, nhưng FrontierMathhiện vẫn chưa phải là thế mạnh của nó — ít nhất là ở thời điểm hiện tại. Việc sử dụng tính năng Agentic thay vì chỉ dùng LLM thuần có thể sẽ cho kết quả tốt hơn.
Các tính năng Agentic
Xiaomi đang đi theo cùng một lối triển khai như MiniMax và Kimi, khi cung cấp tích hợp OpenClaw chỉ với một cú nhấp, cho phép khởi tạo một cloud instance được cấu hình sẵn với MiMo-V2-Pro làm mô hình nền tảng. Không cần thiết lập API, không cần VPS, không cần cấu hình kỹ năng, cũng không phải mất hàng giờ khắc phục lỗi trước khi chạy được tác vụ đầu tiên. Chỉ cần nhấp vào là dùng được.
Môi trường demo chạy trong 30 phút rồi tự hủy — đó là một giới hạn thực sự, nhưng cũng là một cách tiếp cận thẳng thắn. Với các nhà phát triển vốn đã quen với hạ tầng agentic, điều này không mang lại nhiều giá trị bổ sung. Nhưng với phần còn lại, đây có lẽ là điểm vào ít ma sát nhất để tiếp cận AI agentic mà bạn có thể mong đợi.
Kết luận
Xét tổng thể, MiMo-V2-Pro là một mô hình rất đáng gờm, và chúng tôi thực sự thấy hứng thú khi thử nghiệm với nó. Nó không hoàn hảo — trần năng lực ở mảng toán học là có thật, việc công khai chain of thought đã làm lộ ra một lỗi suy luận mà một mô hình kém minh bạch hơn có thể đã che giấu, và mức tiêu thụ token trong các tác vụ suy luận khó tăng lên rất nhanh.
Nếu bạn quan tâm đến chi phí, thì mức giá của Xiaomi là cực kỳ cạnh tranh — chỉ bằng một phần nhỏ so với Claude Opus hay các mô hình mới nhất của OpenAI và Google, trong khi lại tỏ ra mạnh hơn GLM hoặc MiniMax ở những khía cạnh quan trọng nhất đối với công việc sáng tạo và agentic.
Đặc biệt, giới làm sáng tạo nội dung có thể thu được rất nhiều lợi ích từ mô hình này — có khả năng còn nhiều hơn so với những gì họ nhận được từ Anthropic ở thời điểm hiện tại.
Đây là một mô hình suy nghĩ tốn kém, và đó có thể là một đánh đổi. Nếu bạn đang vận hành các pipeline agentic với khối lượng lớn, hãy theo dõi chặt mức đốt token, dù tổng chi phí cuối cùng có thể vẫn thấp hơn so với khi dùng Claude. Còn nếu bạn đang làm những công việc mở, giàu chiều sâu, nơi chất lượng đầu ra là thước đo quan trọng nhất, thì MiMo-V2-Pro hoàn toàn xứng đáng có một vị trí trong danh sách lựa chọn hàng đầu.
Bản tin Daily Debrief
Bắt đầu mỗi ngày với những tin tức nổi bật nhất hiện tại, cùng các bài viết chuyên sâu, podcast, video và nhiều nội dung khác.