Tóm tắt nhanh (In brief)
- Tencent Hy3 preview là mô hình Mixture-of-Experts với 295 tỷ tham số, nhưng chỉ 21 tỷ tham số hoạt động tại một thời điểm, giúp chi phí vận hành thấp hơn nhiều đối thủ cùng phân khúc.
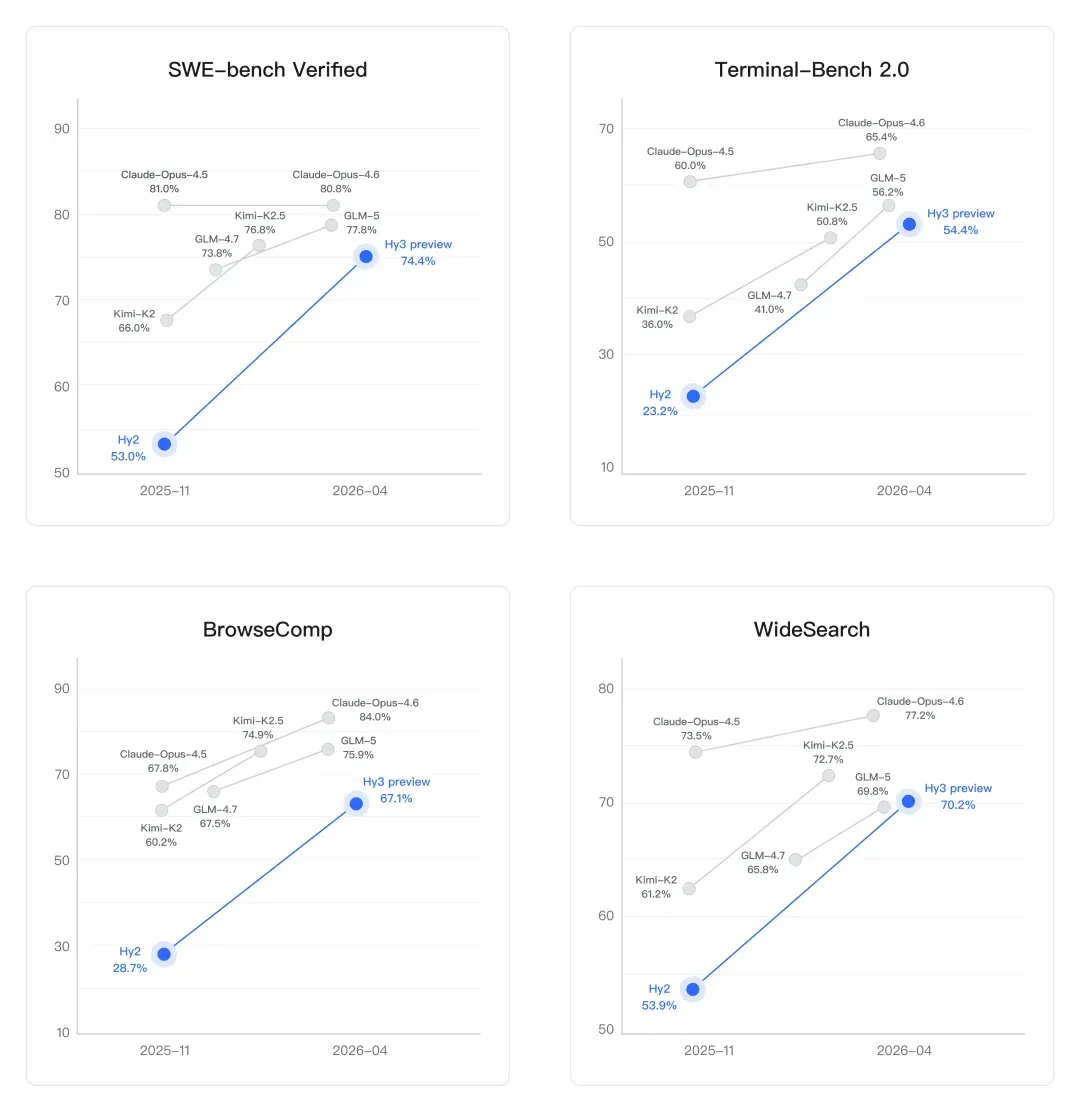
- Trên SWE-bench Verified — benchmark sửa lỗi code thực tế trên GitHub — model tăng từ 53% (Hy2) lên 74,4%, tương đương mức cải thiện 40% so với thế hệ trước.
- Model đã được triển khai trong hệ sinh thái Tencent như Yuanbao, QQ và Tencent Docs, với API trên Tencent Cloud có giá khởi điểm khoảng $0,18/triệu input tokens.
Nội dung chính
Tencent đã âm thầm ra mắt mô hình AI mạnh nhất của mình vào thứ Năm, với các chỉ số benchmark rất đáng chú ý. Hy3 preview — model đầu tiên sau khi hãng tái xây dựng toàn bộ hạ tầng — hiện đã được open-source trên GitHub, Hugging Face và ModelScope.
Model cũng có sẵn trên Tencent Cloud dưới dạng dịch vụ trả phí.
Hy3 sở hữu tổng cộng 295 tỷ tham số (thể hiện độ rộng tri thức), nhưng chỉ kích hoạt 21 tỷ tham số tại mỗi lần xử lý. Đây là ưu điểm của kiến trúc Mixture-of-Experts — model sẽ định tuyến truy vấn đến một nhóm “expert” chuyên biệt thay vì chạy toàn bộ mạng cùng lúc, giúp giảm compute, tối ưu chi phí nhưng vẫn giữ chất lượng đầu ra tương đương. Model cũng hỗ trợ context lên đến 256.000 tokens, đủ để xử lý cả một cuốn tiểu thuyết trong một prompt.
Tencent cho biết Hy3 được thiết kế để cân bằng ba yếu tố mà trước đây khó đạt cùng lúc: độ rộng năng lực, đánh giá trung thực và hiệu quả chi phí. Model tiền nhiệm Hy2 có hơn 400 tỷ tham số, nhưng Tencent đã chủ động giảm xuống 295 tỷ, cho rằng đây là “điểm tối ưu” khi khả năng suy luận đạt độ trưởng thành trong khi chi phí tăng thêm không còn hiệu quả.
Điều này không đồng nghĩa model yếu hơn — thực tế, các mô hình được huấn luyện tốt với ít tham số hơn thường có thể vượt qua các mô hình lớn nhưng kém tối ưu.
Ở mảng coding, bước tiến là rất rõ rệt. Trên SWE-bench Verified — benchmark kiểm tra khả năng sửa lỗi thực tế trên GitHub — Hy2 đạt 53,0% trong khi Hy3 preview đạt 74,4%, tăng khoảng 40% chỉ sau một thế hệ. Thành tích này đưa Hy3 tiệm cận Anthropic Claude Opus 4.6 (80,8%) và vượt qua các model như GLM-5 (77,8%) và Kimi-K2.5 (76,8%).
Ngoài ra, trên Terminal-Bench 2.0 — benchmark đo khả năng thực thi tác vụ tự động trong môi trường dòng lệnh — model cũng tăng mạnh từ 23,2% lên 54,4%.
Tuy nhiên, model này đặc biệt đáng chú ý đối với những người xây dựng hệ thống agent. Agent thường phải xử lý tập hợp chỉ dẫn phức tạp bao gồm memory, skill và các tool call. Chỉ cần bỏ sót một yếu tố nhỏ cũng có thể làm hỏng toàn bộ workflow hoặc tạo ra kết quả kém chất lượng. Chính vì vậy, năng lực agentic ngày càng trở thành yếu tố cốt lõi đối với developer AI khi lĩnh vực này đang là xu hướng “hot” nhất trong ngành. Đây cũng là lý do model được đưa lên Openclaw ngay từ đầu.
Ở mảng search và browsing agent — nơi model phải tự thu thập, lọc và tổng hợp thông tin từ web mà không có sự hướng dẫn của con người — hiệu suất cũng cải thiện mạnh. Trên BrowseComp, Hy3 preview đạt 67,1% (so với 28,7% của Hy2). Trên WideSearch, model đạt 70,2%, vượt GLM-5 và Kimi-K2.5 nhưng vẫn thấp hơn Anthropic Claude Opus 4.6 (77,2%).
Về khả năng reasoning, Tencent Hy3 dẫn đầu các model Trung Quốc trong kỳ thi tuyển sinh tiến sĩ Toán của Tsinghua University (Spring 2026), đạt điểm trung bình 88,4 (avg@3). Đây là bài thi thực tế, không phải dataset được tối ưu sẵn — đúng theo định hướng của Tencent nhằm tránh “benchmark gaming”. Model cũng đạt 87,8 điểm tại CHSBO 2025 (Olympic Sinh học THPT Trung Quốc), cao nhất trong các model nội địa ở hạng mục này.
Hy3 preview bắt đầu được train từ cuối tháng 1/2026 và ra mắt vào thứ Năm — chưa đến 3 tháng từ khi khởi đầu đến khi open-source, một tốc độ hiếm thấy với model quy mô lớn. Tencent cho biết điều này đến từ việc tái cấu trúc hạ tầng vào tháng 2, do trưởng bộ phận AI Yao Shunyu dẫn dắt, bao gồm việc xây dựng lại toàn bộ hệ thống pretraining và reinforcement learning.
Cách tiếp cận này khác biệt đáng kể so với các lab AI Trung Quốc một năm trước, khi DeepSeek gây bất ngờ với model R1 nhờ hiệu quả chi phí.
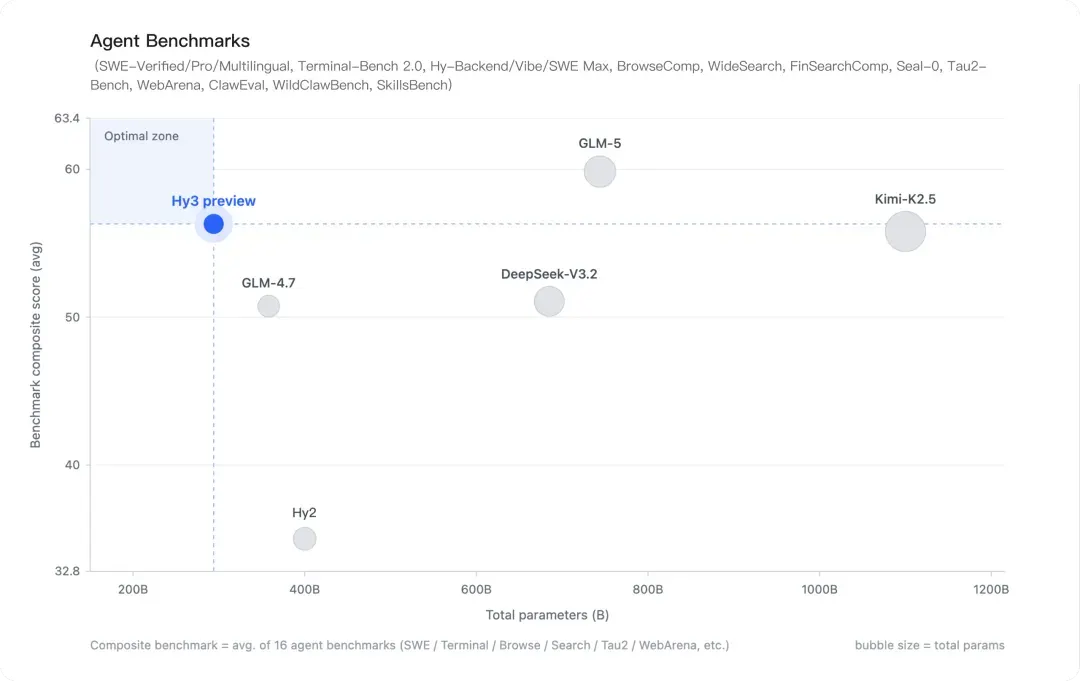
Dù Hy3 vẫn chưa vượt qua các model flagship của OpenAI và Google DeepMind, nhưng xét theo tỷ lệ hiệu suất trên quy mô, Hy3 preview rất khó bị bỏ qua. Trên bảng tổng hợp benchmark về agent, model này nằm trong “vùng tối ưu” với ~295 tỷ tham số, vượt DeepSeek-V3.2 (600+ tỷ tham số) và ngang với Kimi-K2.5 (hơn 1 nghìn tỷ tham số) nhưng chỉ cần chi phí tính toán thấp hơn đáng kể.
Các model Hunyuan đã được triển khai trên các nền tảng như Yuanbao, CodeBuddy, WorkBuddy, QQ và Tencent Docs. Trên CodeBuddy và WorkBuddy, độ trễ token đầu tiên giảm 54%, thời gian sinh nội dung end-to-end giảm 47%, và model có thể thực thi các workflow agent lên đến 495 bước.
Tencent Cloud cung cấp API với mức giá khoảng $0,18 cho mỗi 1 triệu input tokens và $0,59 cho mỗi 1 triệu output tokens, trong khi các gói Token Plan cá nhân bắt đầu từ khoảng $4,10/tháng.
Bản tin Daily Debrief
Bắt đầu mỗi ngày với những tin tức nổi bật nhất, cùng nội dung độc quyền, podcast, video và nhiều hơn nữa.