Tóm tắt nhanh
- Google cho biết thuật toán TurboQuant của họ có thể cắt giảm ít nhất 6 lần một nút thắt lớn về bộ nhớ của AI mà không làm suy giảm độ chính xác trong quá trình suy luận.
- Cổ phiếu nhóm công ty bộ nhớ như Micron, Western Digital và Seagate đã giảm sau khi bài nghiên cứu này được lan truyền.
- Phương pháp này nén bộ nhớ phục vụ suy luận, chứ không nén trọng số mô hình, và cho đến nay mới chỉ được kiểm chứng trên các benchmark nghiên cứu.
Google Research đã công bố TurboQuant vào thứ Tư, một thuật toán nén giúp thu nhỏ một nút thắt lớn về bộ nhớ trong giai đoạn suy luận ít nhất 6 lần, trong khi vẫn duy trì mức độ chính xác không suy giảm.
Bài nghiên cứu này dự kiến sẽ được trình bày tại ICLR 2026, và phản ứng trên mạng xuất hiện gần như ngay lập tức.
CEO Cloudflare Matthew Prince gọi đây là “khoảnh khắc DeepSeek” của Google. Cùng trong ngày, giá cổ phiếu của các công ty bộ nhớ như Micron, Western Digital và Seagate đã đồng loạt giảm.
Vậy điều này có thật không?
Bản thân hiệu quả lượng tử hóa đã là một thành tựu lớn. Nhưng tuyên bố “không mất độ chính xác” cần được đặt trong đúng ngữ cảnh.
TurboQuant nhắm vào KV cache — phần bộ nhớ GPU dùng để lưu mọi thứ mà một mô hình ngôn ngữ cần “ghi nhớ” trong suốt một cuộc hội thoại.
Khi cửa sổ ngữ cảnh mở rộng lên hàng triệu token, các bộ nhớ đệm này có thể phình to lên đến hàng trăm gigabyte cho mỗi phiên làm việc. Đó mới là nút thắt thực sự — không phải năng lực tính toán, mà là dung lượng bộ nhớ thô.
Các phương pháp nén truyền thống thường cố thu nhỏ các cache này bằng cách làm tròn dữ liệu xuống — chẳng hạn từ số thực dấu chấm động 32-bit xuống 16-bit, rồi 8-bit, rồi số nguyên 4-bit. Để dễ hình dung, có thể xem nó giống như việc giảm độ phân giải hình ảnh từ 4K xuống Full HD rồi xuống 720p. Bạn vẫn nhận ra đó là cùng một bức ảnh, nhưng mức độ chi tiết ở 4K rõ ràng cao hơn.
Điểm đánh đổi nằm ở chỗ: các phương pháp đó phải lưu thêm các “hằng số lượng tử hóa” bên cạnh dữ liệu đã nén để tránh làm mô hình suy giảm chất lượng quá mạnh. Những hằng số này làm phát sinh thêm 1 đến 2 bit cho mỗi giá trị, khiến lợi ích nén bị bào mòn một phần.
TurboQuant tuyên bố loại bỏ hoàn toàn phần overhead đó.
Google thực hiện điều này thông qua hai thuật toán con. PolarQuant tách độ lớn ra khỏi hướng trong các vector, còn QJL (Quantized Johnson-Lindenstrauss) lấy phần sai số dư rất nhỏ còn lại và rút gọn nó xuống chỉ còn một bit dấu — dương hoặc âm — mà không cần lưu thêm bất kỳ hằng số nào.
Kết quả, theo Google, là một bộ ước lượng không chệch về mặt toán học cho các phép tính attention — cơ chế cốt lõi vận hành các mô hình transformer.
Trong các benchmark sử dụng Gemma và Mistral, TurboQuant cho kết quả tương đương với độ chính xác đầy đủ ngay cả khi nén 4 lần, bao gồm cả việc giữ được độ chính xác truy xuất hoàn hảo trong các bài kiểm tra “needle-in-haystack” với ngữ cảnh dài tới 104.000 token.
Để hiểu vì sao các benchmark này quan trọng: việc mở rộng ngữ cảnh hữu dụng của mô hình mà không làm giảm chất lượng từ lâu đã là một trong những bài toán khó nhất trong triển khai LLM.
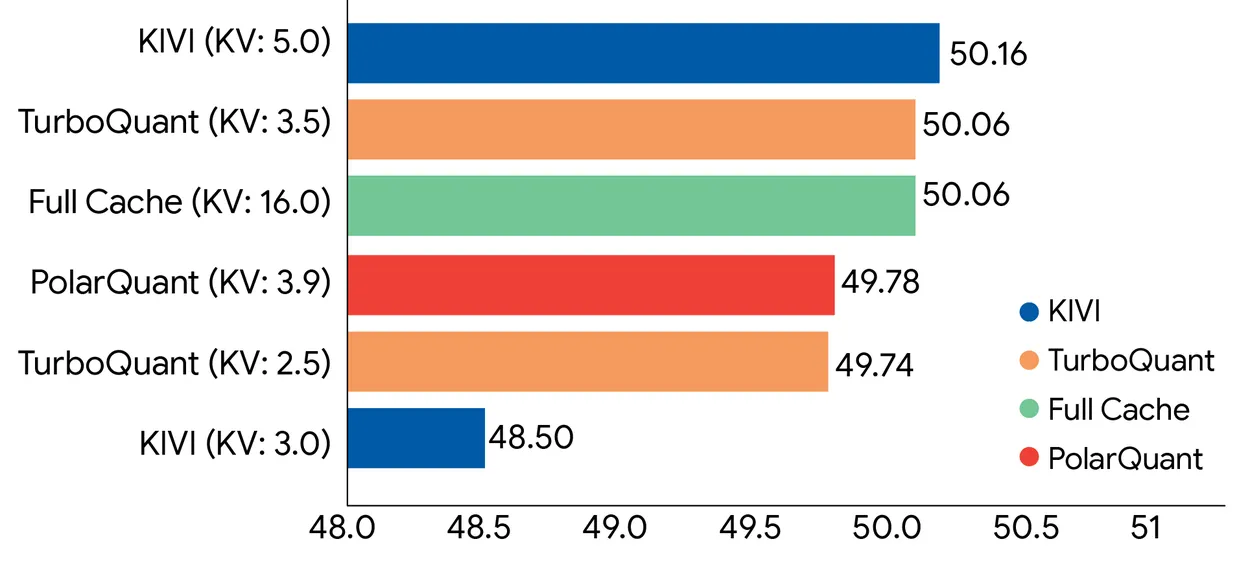
Cụm từ “không mất độ chính xác” ở đây chỉ áp dụng cho việc nén KV cache trong quá trình suy luận — chứ không áp dụng cho trọng số của mô hình. Nén trọng số là một bài toán hoàn toàn khác và khó hơn nhiều. TurboQuant không can thiệp vào phần đó.
Thứ mà TurboQuant nén là vùng bộ nhớ tạm thời dùng để lưu các phép tính attention giữa chừng trong một phiên suy luận. Phần dữ liệu này dễ “chịu nén” hơn, vì về mặt lý thuyết nó có thể được tái dựng lại.
Ngoài ra còn có khoảng cách giữa một benchmark sạch trong môi trường nghiên cứu và một hệ thống production phải phục vụ hàng tỷ request. TurboQuant được thử nghiệm trên các mô hình mã nguồn mở — như Gemma, Mistral và Llama — chứ chưa phải trên hạ tầng Gemini của chính Google ở quy mô thực tế.
Khác với các bước tiến về hiệu quả của DeepSeek — vốn đòi hỏi những quyết định kiến trúc sâu được tích hợp ngay từ đầu — TurboQuant không cần retrain hay fine-tune lại mô hình, đồng thời được cho là gần như không tạo thêm chi phí runtime đáng kể. Về lý thuyết, nó có thể được tích hợp trực tiếp vào các pipeline suy luận hiện có.
Chính điểm này đã khiến nhóm cổ phiếu phần cứng bộ nhớ phản ứng mạnh — bởi nếu công nghệ này hoạt động tốt trong môi trường production, các phòng lab AI lớn có thể vận hành tiết kiệm hơn trên chính số GPU mà họ đã sở hữu.
Bài nghiên cứu này sẽ được trình bày tại ICLR 2026. Cho đến khi nó thực sự được triển khai trong môi trường production, tuyên bố “không mất độ chính xác” vẫn mới chỉ dừng lại trong phòng thí nghiệm.
Bản tin Daily Debrief
Bắt đầu mỗi ngày với những tin tức nổi bật nhất hiện tại, cùng các bài viết gốc, podcast và nhiều nội dung khác.