Tóm tắt ngắn:
- Anthropic đã phát hành Claude Opus 4.8 vào thứ Năm, chỉ sáu tuần sau khi ra mắt Opus 4.7.
- Bản cập nhật mang lại những cải thiện về kỹ thuật phần mềm, khả năng suy luận và thao tác trên máy tính, trong khi mức giá vẫn giữ nguyên ở 5 USD cho mỗi triệu token đầu vào và 25 USD cho mỗi triệu token đầu ra.
- Điểm số về độ an toàn và khả năng tuân thủ của Opus 4.8 hiện đã tiệm cận Claude Mythos Preview – mô hình tiên tiến nhưng bị giới hạn truy cập của Anthropic. Tỷ lệ hành vi mang tính lừa dối hoặc dễ bị lạm dụng cũng giảm đáng kể so với phiên bản trước.
Sáu tuần. Đó là khoảng thời gian Anthropic cần để chuyển từ Opus 4.7 lên Opus 4.8.
Mô hình mới nhanh hơn và thông minh hơn trên các bài kiểm tra benchmark, đồng thời được bổ sung nhiều tính năng mới. Tuy nhiên, mức giá không thay đổi: 5 USD cho mỗi triệu token đầu vào và 25 USD cho mỗi triệu token đầu ra.
Anthropic cũng giới thiệu chế độ Fast Mode, sử dụng cùng một mô hình nhưng chạy nhanh gấp 2,5 lần với mức giá 10 USD cho mỗi triệu token đầu vào và 50 USD cho mỗi triệu token đầu ra. Công ty cho biết mức giá này rẻ hơn khoảng 3 lần so với Fast Mode trên các thế hệ trước, đồng nghĩa với việc chế độ này từng đắt đỏ hơn đáng kể.
SWE-bench Pro được xem là một trong những benchmark quan trọng nhất để đánh giá năng lực của mô hình. Bài kiểm tra này đo lường khả năng AI giải quyết các vấn đề kỹ thuật phần mềm phức tạp, đa ngôn ngữ, lấy từ các mã nguồn sản phẩm thực tế, và được chấm điểm dựa trên tỷ lệ bài toán được giải quyết thành công.
Trên bài kiểm tra này, Opus 4.8 đạt 69,2%, tăng từ mức 64,3% của Opus 4.7. Trong khi đó, GPT-5.5 của OpenAI đạt 58,6% và Gemini 3.1 Pro của Google đạt 54,2%. Với một mô hình có cùng mức giá, đây là một bước tiến đáng kể.
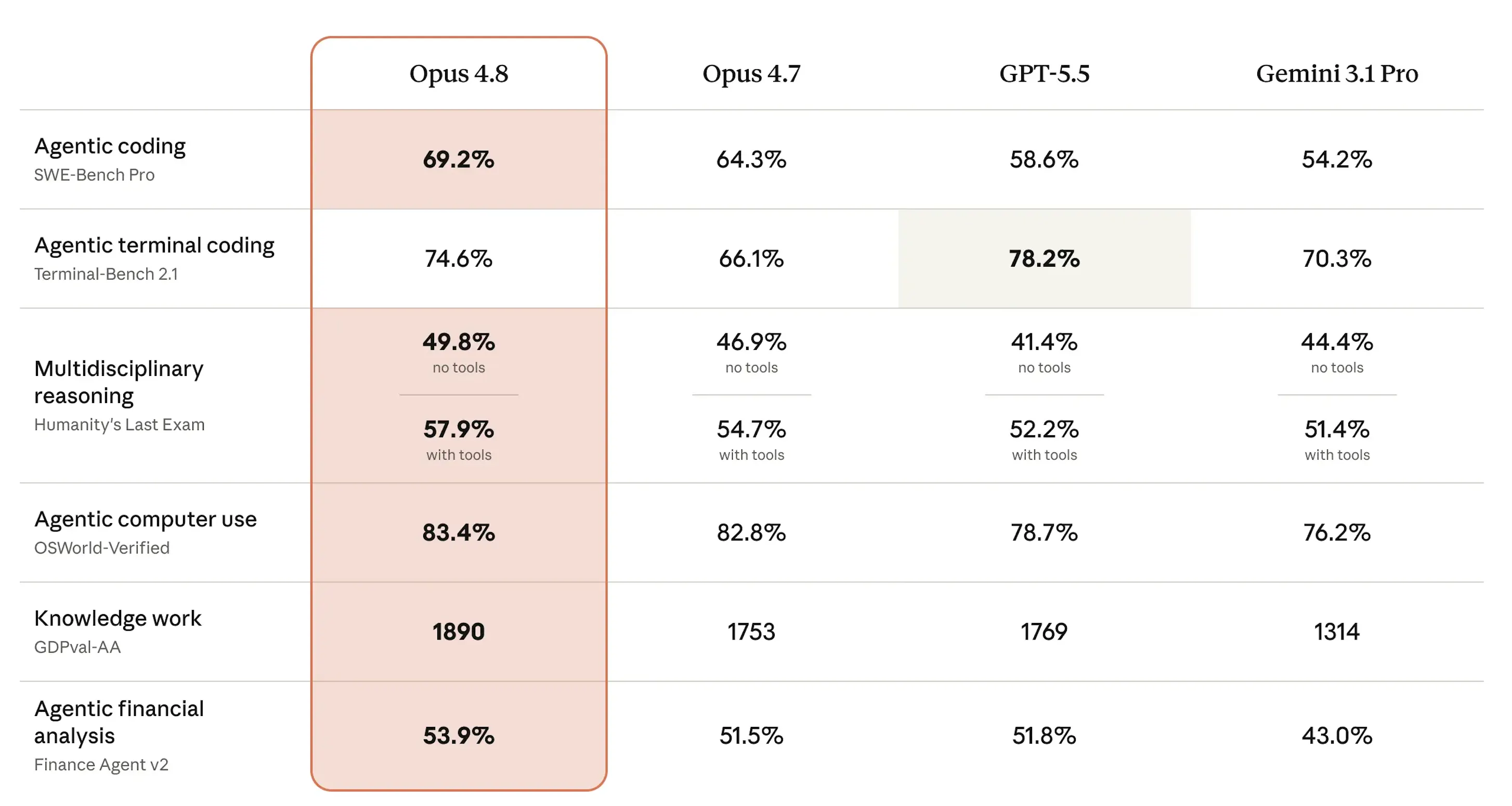
Trên bài kiểm tra Humanity’s Last Exam — tập hợp các câu hỏi ở trình độ chuyên gia thuộc hàng chục lĩnh vực học thuật khác nhau, được chấm theo tỷ lệ trả lời đúng — Opus 4.8 đạt 49,8% khi không sử dụng công cụ hỗ trợ và 57,9% khi được phép sử dụng công cụ, vượt qua cả ba đối thủ cạnh tranh.
Ở bài kiểm tra OSWorld-Verified, vốn đánh giá khả năng thực hiện các tác vụ sử dụng máy tính trong môi trường thực tế như điều hướng giao diện phần mềm và thao tác trên ứng dụng, Opus 4.8 đạt 83,4%, nhỉnh hơn một chút so với mức 82,8% của Opus 4.7.
Điểm trừ duy nhất nằm ở Terminal-Bench 2.1, bài kiểm tra đo lường hiệu suất của AI trong các tác vụ dòng lệnh (command-line). GPT-5.5 dẫn đầu với 78,2%, trong khi Opus 4.8 đạt 74,6% — cao hơn đáng kể so với mức 66,1% của Opus 4.7 và vượt qua Gemini với 70,3%, nhưng vị trí thứ hai vẫn là vị trí thứ hai.
Năm góc nhìn để đánh giá (Five ways to think).
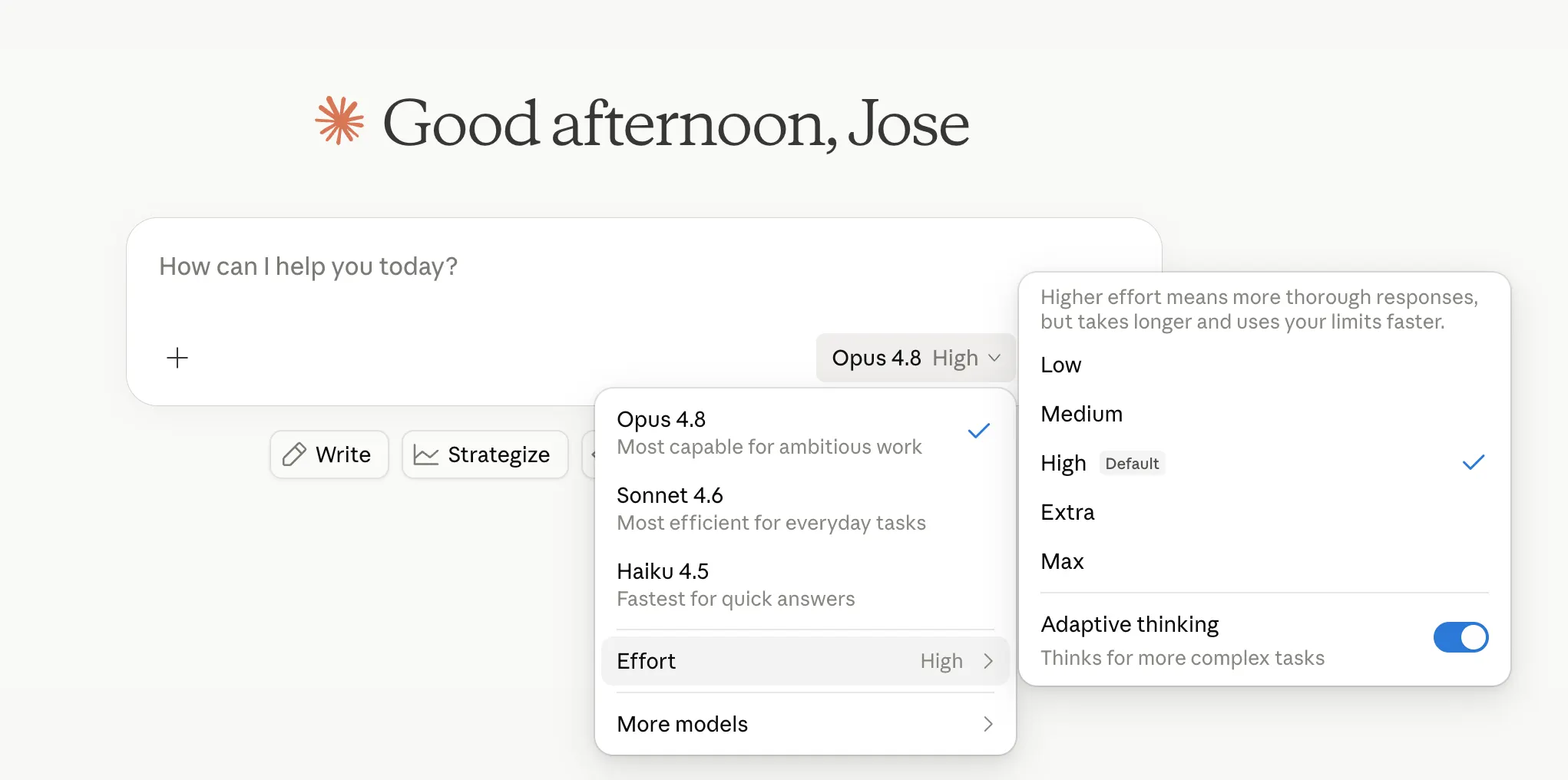
Anthropic hiện cho phép người dùng kiểm soát mức độ “suy nghĩ” của mô hình.
Mức High là mặc định và đủ tốt cho hầu hết các tác vụ. Extra — được gọi là xhigh trong Claude Code — sử dụng nhiều tài nguyên tính toán hơn để xử lý các bài toán khó. Max là mức cao nhất, dành cho những tác vụ đòi hỏi khả năng suy luận sâu. Trong khi đó, Low và Medium sử dụng ít token hơn cho cùng một nhiệm vụ, giúp tiết kiệm thời gian và chi phí nhưng đánh đổi bằng độ chính xác.
Tùy chọn điều chỉnh mức độ suy luận được đặt cạnh bộ chọn mô hình trên Claude.ai và Cowork, đồng thời có mặt trên tất cả các gói dịch vụ. Anthropic cho biết mức High mặc định tiêu thụ lượng token tương đương với mức mặc định của Opus 4.7 nhưng cho kết quả tốt hơn — điều này có thể là thành quả của kỹ thuật tối ưu ấn tượng, hoặc đơn giản là cách truyền thông hiệu quả, và có lẽ là cả hai.
Cũng cần lưu ý rằng bộ tokenizer mới của Opus sử dụng nhiều token hơn cho mỗi tác vụ. Điều này đồng nghĩa người dùng Claude có thể sẽ tốn nhiều chi phí hơn để hoàn thành công việc nếu chọn Opus thay vì Claude Sonnet — một mô hình kém mạnh hơn nhưng vẫn đủ đáp ứng phần lớn nhu cầu hằng ngày và các bài toán phức tạp chưa đến mức nghiên cứu khoa học tiên tiến hoặc lập trình chuyên sâu.
Anthropic cũng đã tăng giới hạn sử dụng (rate limits) trong Claude Code để bù đắp cho lượng token tiêu thụ cao hơn khi người dùng chọn các chế độ Extra hoặc Max.
Gần an toàn ngang với Claude Mythos.
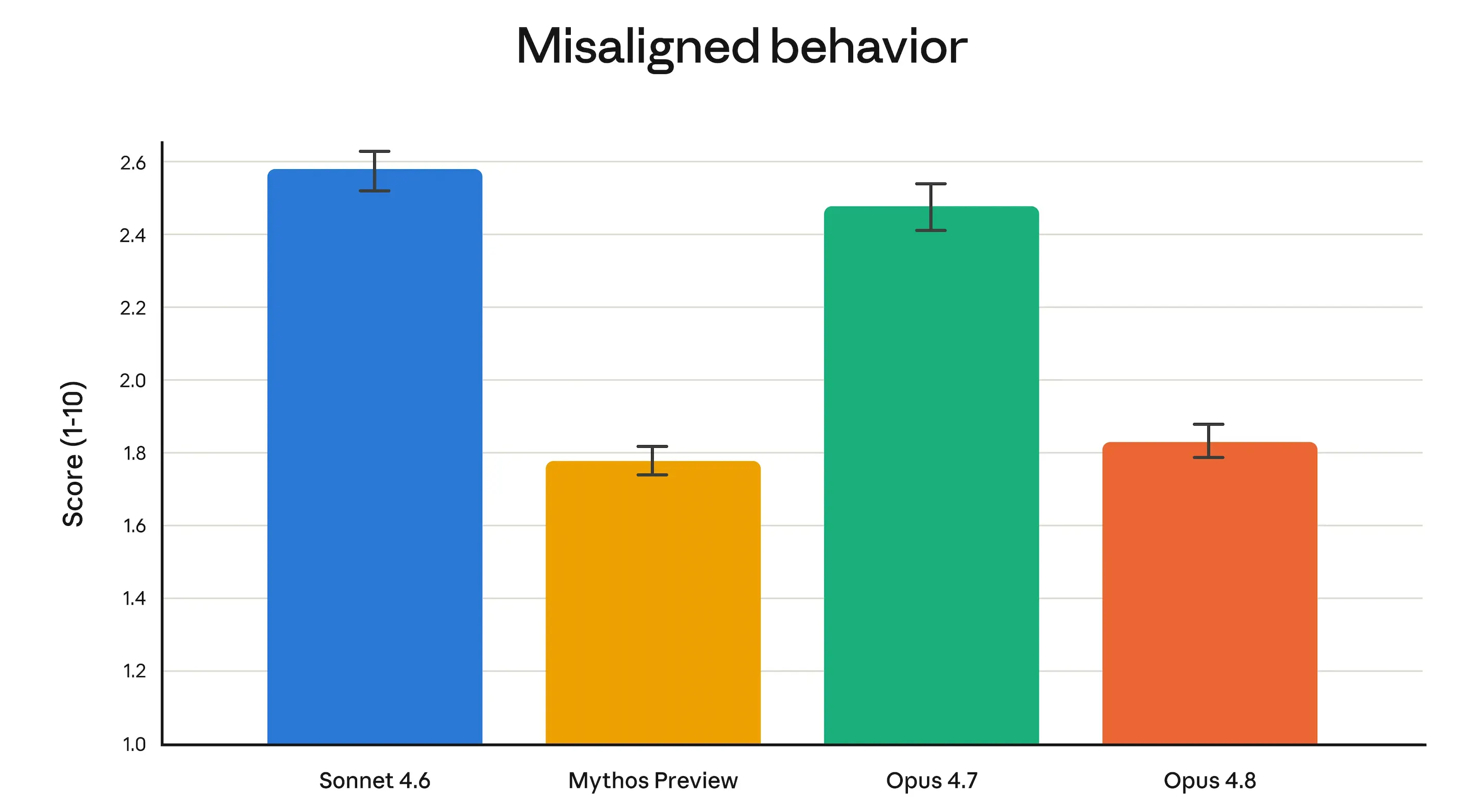
Nhóm nghiên cứu căn chỉnh (alignment) của Anthropic cho biết Opus 4.8 “đạt những mức cao mới trong các thước đo về các đặc tính hướng đến lợi ích xã hội như hỗ trợ quyền tự chủ của người dùng và hành động vì lợi ích tốt nhất của họ”. Cụ thể hơn, tỷ lệ hành vi mang tính lừa dối và tỷ lệ hợp tác với các yêu cầu có khả năng bị lạm dụng đã thấp hơn đáng kể so với Opus 4.7, đồng thời tương đương với Claude Mythos Preview — mô hình được kiểm soát nghiêm ngặt nhất của Anthropic.
Opus 4.8 cũng có khả năng bỏ sót lỗi trong chính đoạn mã do nó tạo ra thấp hơn 4 lần so với phiên bản 4.7.
Tuy nhiên, việc so sánh với Mythos cần được đặt trong đúng bối cảnh. Mythos là một cấp độ hoàn toàn cao hơn Opus — Anthropic mô tả đây là mô hình “lớn hơn và thông minh hơn các mô hình Opus của chúng tôi”. Hiện tại, nó chỉ tồn tại dưới dạng bản xem trước (preview), được cung cấp cho một số ít tổ chức đã được thẩm định tham gia các hoạt động an ninh mạng thông qua Project Glasswing.
Viện An ninh AI của Vương quốc Anh phát hiện Mythos có thể tự động hoàn thành “The Last Ones”, một bài mô phỏng tấn công mạng doanh nghiệp gồm 32 bước, vốn thường mất khoảng 20 giờ để các đội red team của con người thực hiện. Đó là lý do mô hình này vẫn chưa được bán ra thị trường. Anthropic cho biết các biện pháp bảo vệ an ninh mạng mạnh mẽ hơn đang được phát triển và kỳ vọng sẽ đưa các mô hình đạt cấp độ Mythos đến với mọi người “trong vài tuần tới”.
Cũng được phát hành hôm nay là Dynamic Workflows trong Claude Code dưới dạng bản xem trước nghiên cứu. Tính năng này cho phép Claude tự viết các kịch bản điều phối công việc, tự tạo nhiều tác nhân phụ chạy song song trong cùng một phiên làm việc, kiểm tra kết quả của chúng và tổng hợp báo cáo cuối cùng — tương tự như những gì Hermes đã thực hiện từ khá lâu.
Dynamic Workflows hiện khả dụng cho người dùng các gói Enterprise, Team và Max. Anthropic cũng thẳng thắn cho biết tính năng này tiêu tốn lượng token nhiều hơn đáng kể so với một phiên Claude Code thông thường.
Khoảng cách giá ngày càng lớn
Mức giá 5 USD cho mỗi triệu token đầu vào và 25 USD cho mỗi triệu token đầu ra của Anthropic trông rất khác khi đặt cạnh những gì các công ty AI Trung Quốc đang làm gần đây.
Tuần trước, DeepSeek V4 Pro đã biến chương trình giảm giá 75% thành chính sách vĩnh viễn: 0,435 USD cho mỗi triệu token đầu vào và 0,87 USD cho mỗi triệu token đầu ra. Xiaomi MiMo V2.5 Pro cũng có mức giá tương tự thông qua các nhà cung cấp như OpenRouter.
Chế độ Fast Mode của Anthropic có giá 10 USD cho mỗi triệu token đầu vào và 50 USD cho mỗi triệu token đầu ra — đắt hơn cả Opus 4.8 tiêu chuẩn, đồng thời chi phí token đầu ra cao hơn khoảng 57 lần so với DeepSeek V4 Pro. Các doanh nghiệp đã chi hàng triệu USD cho chi phí suy luận (inference) trên các mô hình AI của Mỹ. Nếu sử dụng Opus ở quy mô lớn, doanh nghiệp của bạn hoàn toàn có thể nhanh chóng tiêu tốn hàng triệu USD.
Câu trả lời của Anthropic cho khoảng cách giá này là chất lượng và độ an toàn. Trên bài kiểm tra SWE-bench Pro, Opus 4.8 vượt qua cả hai mô hình Trung Quốc. Về khả năng căn chỉnh (alignment), cả hai đối thủ cũng chưa thể tiệm cận các kết quả benchmark mà Anthropic công bố.
Những yếu tố này đặc biệt quan trọng trong các môi trường vận hành thực tế, nơi việc một mô hình âm thầm hợp tác với các đầu vào nguy hiểm có thể trở thành rủi ro nghiêm trọng — chẳng hạn như trong các ngành được quản lý chặt chẽ, lĩnh vực pháp lý hoặc bất kỳ nơi nào mà câu giải thích “lúc đó có vẻ ổn” không thể được chấp nhận sau khi sự cố xảy ra.
Đối với phần lớn những người dùng còn lại, khoảng cách về giá là điều rất khó để bỏ qua.
Chúng tôi đã thử nghiệm nó.
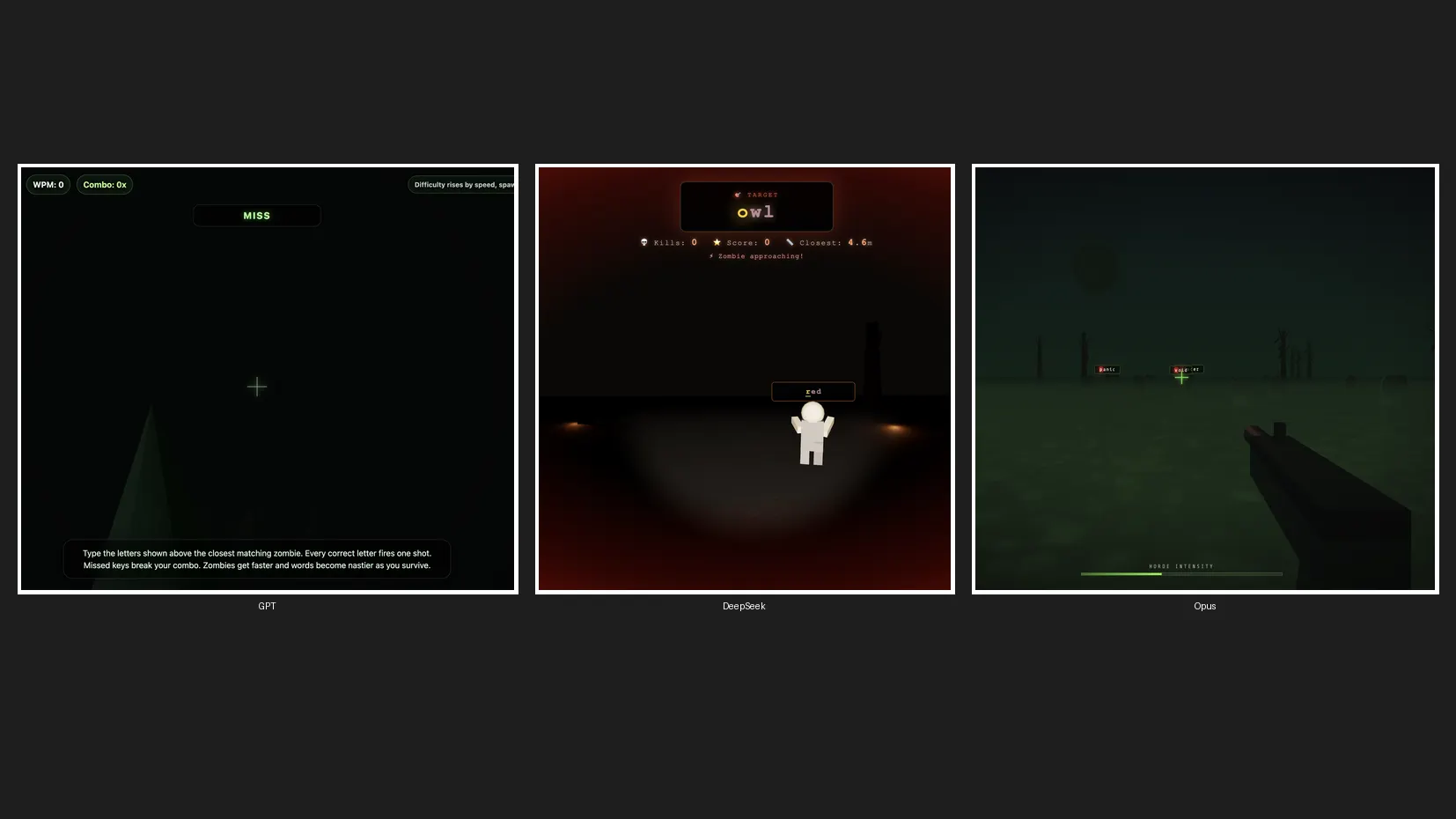
Chúng tôi đã thực hiện một bài kiểm tra lập trình nhanh bằng cách yêu cầu các mô hình tạo một trò chơi zombie 3D để xem Claude Opus 4.8 thể hiện như thế nào so với ChatGPT và DeepSeek — có lẽ là hai đối thủ phổ biến nhất của nó đến từ Mỹ và Trung Quốc.
Chúng tôi thiết lập Opus 4.8 ở mức suy luận mặc định High, GPT-5.5 ở mức High Effort, và DeepSeek V4 Pro cũng ở mức High Effort — ba mô hình, một câu lệnh, không thử lại lần nào.
GPT-5.5 hoàn thành đầu tiên. Tuy nhiên, trò chơi của nó không có hình ảnh zombie và cũng không có hiệu ứng âm thanh. Nó nhanh thật, nhưng lại bỏ lỡ hoàn toàn yêu cầu ban đầu.
DeepSeek V4 Pro về nhì với khả năng điều khiển bằng chuột, nhân vật zombie thực sự, hiệu ứng âm thanh, cơ chế gameplay ổn định và giao diện đẹp mắt. Không có nhiều điều để phàn nàn.
Opus 4.8 mất thời gian lâu hơn khoảng ba lần so với GPT-5.5, nhưng lại tạo ra màn hình khởi động đẹp nhất, thiết kế zombie tốt nhất, cơ chế trò chơi hay nhất và hiệu ứng âm thanh khá ổn. Đây là mô hình chậm nhất, nhưng cũng cho ra kết quả tốt nhất. Dù vậy, điều đó có lẽ vẫn chưa đủ để biện minh cho việc sử dụng nó thay vì DeepSeek, khi xét đến khoảng cách rất lớn về chi phí.
Tất cả các trò chơi đều đã được đăng tải trên trang Itch.io của chúng tôi. GPT-5.5 tạo ra trò chơi Zombie Typing, Opus tạo ra Typing Dead, còn DeepSeek V4 Pro tạo ra một trò chơi không có tên và đưa người chơi vào hành động ngay lập tức. Chúng ta tạm gọi nó là TypeSeek.
Một bài đánh giá so sánh chi tiết sẽ sớm được công bố. Còn ở thời điểm hiện tại, có thể kết luận rằng: Claude Opus 4.8 lập trình tốt hơn GPT-5.5 và Opus 4.7 trong loại tác vụ này, trong khi vẫn giữ nguyên mức giá mà Anthropic áp dụng từ thời Opus 4.7.
Những nhà phát triển vốn đã trả 5 USD cho mỗi triệu token giờ đây đơn giản là được sử dụng một mô hình tốt hơn mà không phải trả thêm chi phí.
Bản tin Daily Debrief
Bắt đầu mỗi ngày với những tin tức nổi bật nhất hiện tại, cùng các bài viết chuyên sâu, podcast, video và nhiều nội dung khác.